Lec2.1 Basic of ML
本讲将复习机器学习的基础知识,并通过softmax回归作为示例演示所有机器学习算法的基本构成部分。
本讲将快速浏览基础机器学习知识,你之前应该已经接触过这方面的知识。如果你以前没有接触过,或者以前接触过的形式略有不同,那没关系,但是如果这些都是全新的知识,那么在参加这个更加系统化和稍微高级的课程之前,你可能需要学习一些更基础的机器学习课程。
本节课将讨论两个主题:
机器学习的基础知识
使用softmax回归或多类别逻辑回归作为例子来说明这些思想。

Machine learning as data-driven programming
首先,让我们来谈一谈机器学习的基础知识。
假设你有以下任务,实际上你的作业中也会有类似的任务:你想要处理手写数字的图像,就像你在右侧看到的这张图片一样,并编写一个程序将其分类到十个不同的类别中,也就是数字0到9。
现在,你可以采用几种方法来完成这个任务,
传统的方法是:你需要花一些时间仔细思考数字的本质你需要想一想,什么让一个“0”成为一个“0”;至少就图像而言?什么让一个“1”成为一个“1”,等等。然后,你需要将这种逻辑封装在一个计算机程序中。这是我们学习编码大多数事物的方式。当我们需要像排序列表这样的任务时,这种方法实际上是很好的,因为我们可以在逻辑上结构化地组织每个步骤所需的前提条件和后置条件,并构建逻辑。
但对于许多类似这样的任务(比如图像任务),这最终会成为一个相当困难的问题。因此,我们需要寻找其他解决这些问题的方法。
计算机不像人类一样看待图像,我们看到这些数字,我们立刻就能看到它们的形式、结构等,但计算机却不是这样的。如何构建关于如何创建一个“3”和这些数字之间的关系的逻辑?它们涉及哪些形状?哪些像素值?如何将像素值的网格转化为数字的实际分类?实际上,对我来说编写这样的程序会很困难。因此,我们需要探索其他解决这些问题的方法,至少我们希望能够找到其他的解决方法。这正是机器学习所能提供的。
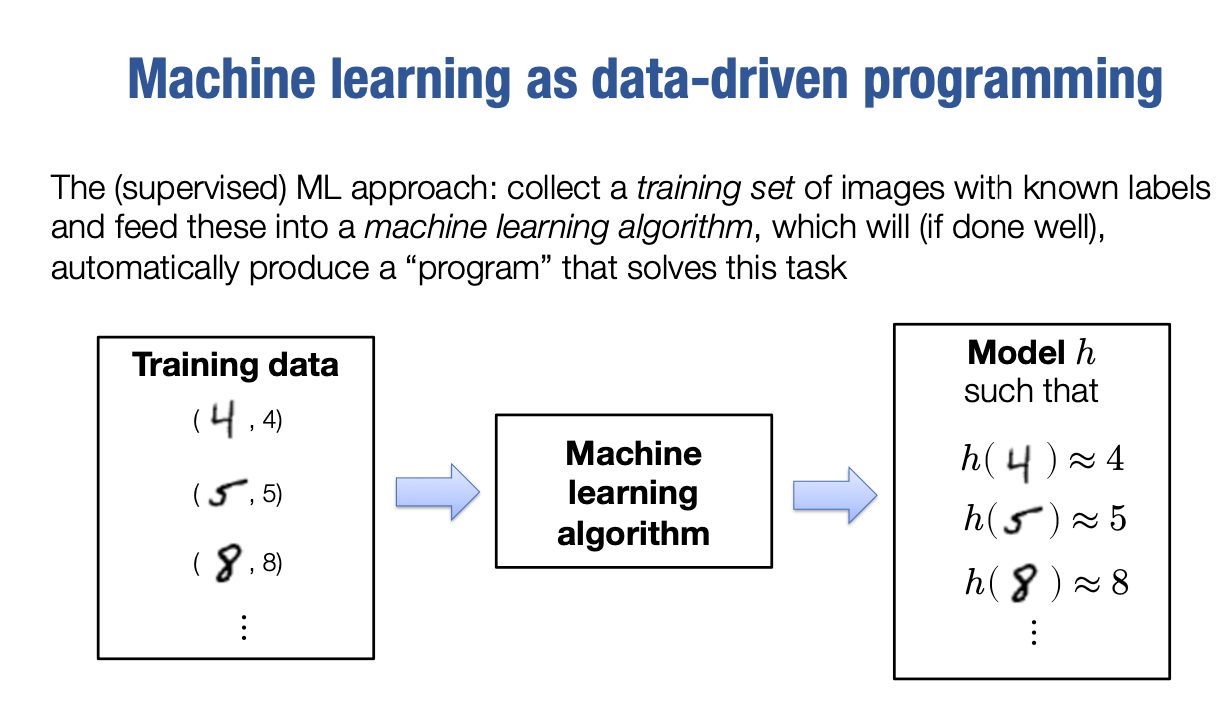
现在,解决这个问题的机器学习方法是监督学习。在这门课中,我们将主要涵盖监督学习。但是在课程后期,我们也会涉及一些无监督学习的内容。
但是,对于这个问题,监督学习范式是这样的
我们很难编写一个能够对这些数字进行分类的程序,但对于人类来说相对容易的事情是,收集一些带有已知标签或我们要预测的已知目标的数字图像。我们收集这些数据,称之为训练数据集。我们的训练数据集基本上包括这些图像:这个左边的东西是一个数字“4”的图像,还有它的真实标签“4”。
然后我们将这些训练数据输入到一个机器学习算法中。这个算法会产生一个模型h,产生一个我们称之为h的模型或假设,或者你可以把它看作是一个小程序。
这个程序的工作方式是:如果你输入像这些图像一样的例子,它将产生输出“4”,至少是近似的。因此,如果我输入在训练数据集中看到的这些图像,这将产生期望的输出。当然,这个问题的重要之处在于,如果你做得很好,它不仅可以应用于我们训练数据中的示例,而且也可以应用于数字的一般图像。
我们实际上不会在这里讨论泛化的细节以及什么样的函数是好的且具有泛化性。因为我们将在这门课程的大部分时间里,以及在这个课程中主要涵盖的内容是这个框。
今天我想要讲解的是,这个框里面究竟有什么?它到底包含了什么?

因此,这个盒子实际上包含了三个要素。实际上,每个机器学习算法或多或少都包括了这三个不同的要素。这三个不同的要素如下:
第一要素是假设函数(假设类)。因此,这基本上指定了我们使用机器学习算法创建的模型h的结构是什么?
通常情况下,我们说,这个模型是由一组参数参数化的。这些参数所做的是指定这种映射的确切性质,它们指定了一个模型的特定实例将如何从其输入映射到其输出。
第二个要素是损失函数。损失函数指定了一个好的假设是什么?我们如何表征假设在这个问题上的表现?
机器学习的最后一个要素是优化过程。这基本上是我们优化参数的方式,以找到一个参数集,这个参数集大致上可以最小化我们的训练集上的损失总和。
令人惊奇的是,所有机器学习算法,无论是深度学习算法,还是简单的线性分类器、梯度提升,或者实际上你可以提出的任何算法,所有这些算法,(至少是监督学习,尽管无监督学习也在某种程度上也符合)符合这个模式。
Last updated