Lec5
def __add__(self, other):
if isinstance(other, Tensor):
return needle.ops.EWiseAdd()(self, other)
else:
return needle.ops.AddScalar(other)(self)在Python中,
other通常是一个表示与当前对象进行操作的另一个对象或值。它是一个通用的名称,可以代表任何类型的对象,具体取决于上下文和操作的类型。在特殊方法(例如
__add__、__sub__、__mul__等)中,other通常表示与当前对象进行操作的另一个对象。这可以是相同类型的对象,也可以是不同类型的对象。__add__是在Python中用于加法操作的重载符号。当我们对两个对象使用加号运算符时(例如a + b),Python会尝试调用对象的__add__方法来执行加法操作。在该方法的实现中,首先通过
isinstance(other, Tensor)判断参数other是否是Tensor类的实例。如果是,表示进行的是张量间的加法操作。如果
other是Tensor类的实例,代码调用了needle.ops.EWiseAdd()创建一个EWiseAdd操作的实例,并将self和other作为参数传递给它。EWiseAdd是一个用于执行张量逐元素加法的操作。如果
other不是Tensor类的实例,表示进行的是张量与标量之间的加法操作。代码调用了needle.ops.AddScalar(other)创建一个AddScalar操作的实例,并将other作为参数传递给它。AddScalar是一个用于将标量加到张量的每个元素上的操作。根据
Op类的定义,它是一个操作符的抽象基类,定义了一些必须实现的方法。其中包括__call__、compute和gradient方法。Op类的__call__方法在基类中引发了NotImplementedError,意味着该方法需要在子类中进行实现。Op类的compute方法用于计算操作符的前向传播,接受参数args作为输入。在基类中同样引发了NotImplementedError,需要在子类中进行实现。Op类的gradient方法用于计算给定输出梯度的每个输入值的偏导数。它接受out_grad(对输出值的梯度)和node(前向评估的值节点)作为参数,并返回输入节点的偏导数。同样,基类中引发了NotImplementedError,需要在子类中进行实现。EWiseAdd类是Op类的子类,因此继承了Op类的这些方法。在EWiseAdd类中,它实现了compute和gradient方法,定义了逐元素相加的计算和梯度计算。而__call__方法并未在EWiseAdd类中实现,因此会调用父类Op中的__call__方法。所以,尽管
EWiseAdd类没有具体实现__call__方法,但它通过继承自父类Op来继承了__call__方法。调用needle.ops.EWiseAdd()(self, other)时,会调用父类Op的__call__方法,并在其中调用Tensor.make_from_op方法。而EWiseAdd类具体实现了compute和gradient方法,用于执行逐元素相加的计算和梯度计算。那么
def __call__(self, args)里的表示什么?在函数定义中,
*args使用了*运算符,它被称为"可变位置参数"或"星号参数"。它的作用是允许函数接受任意数量的位置参数,并将这些参数作为一个元组传递给函数体内部。needle.ops.EWiseAdd()(self, other)是在调用needle库里面ops.py的方法EwiseAdd()方法嘛?但是在ops.py里面是这样的,为什么不调用add方法?
您是正确的,
needle.ops.EWiseAdd()(self, other)是调用了needle库中ops.py中的EWiseAdd类的实例,并通过实例调用了__call__方法。EWiseAdd类是一个继承自TensorOp的类,它实现了逐元素相加的操作。在EWiseAdd类中,有一个compute方法用于执行实际的计算操作,以及一个gradient方法用于计算梯度。在
ops.py中,还定义了一个名为add的函数,它是EWiseAdd类的便捷方式,用于执行逐元素相加的操作。该函数在内部创建了EWiseAdd类的实例,并通过实例调用了__call__方法来执行计算。因此,您可以选择调用
add函数来执行逐元素相加的操作,如needle.ops.add(a, b)。这样可以更加简洁地进行计算,而不需要直接实例化EWiseAdd类。使用
needle.ops.EWiseAdd()(self, other)的方式可能是因为在该上下文中,需要对EWiseAdd类进行更多的自定义或者使用EWiseAdd类的其他方法,所以直接实例化了EWiseAdd类并调用了__call__方法。
在这段代码中,Tensor.__new__(Tensor)实际上是在动态分配一块内存来创建一个新的 Tensor 对象。
__new__() 是一个用于创建实例的特殊方法。它是在一个类实例化时被调用的,用于创建这个类的实例对象。与 __init__() 方法不同,__new__() 在实例创建之前被调用,因此它负责创建实例并返回它。
在这里,Tensor.__new__(Tensor) 创建了一个新的 Tensor 实例对象,分配了一块内存用于存储该对象的属性和方法。然后,通过调用 _init(op, inputs) 方法进行初始化,将 op 和 inputs 参数传递给 Tensor 对象进行初始化设置。
LAZY_MODE
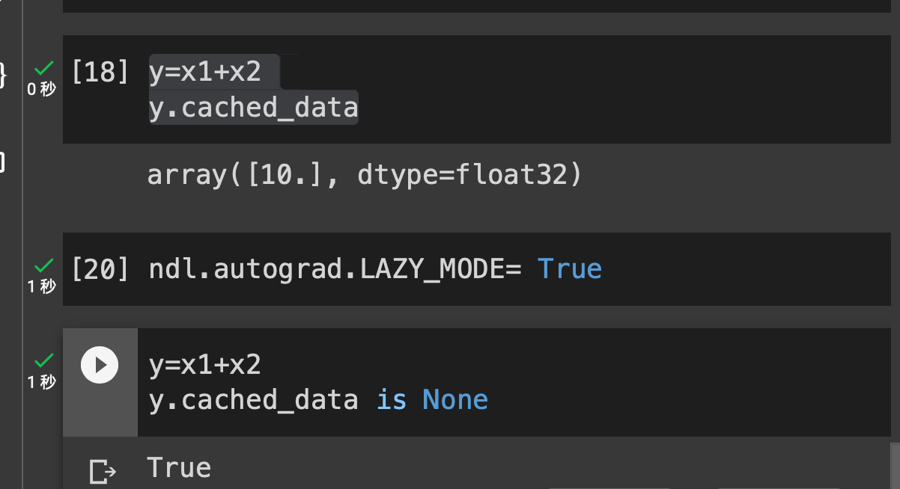
所以,
*[x.realize_cached_data() for x in self.inputs]将会将列表推导式生成的列表解包成独立的位置参数,并传递给函数的*args参数。这样,compute方法中的args参数将成为一个元组,其中包含了所有输入节点的实现缓存数据
**NDArray is numpy array **
Eager Mode && Lazy Mode
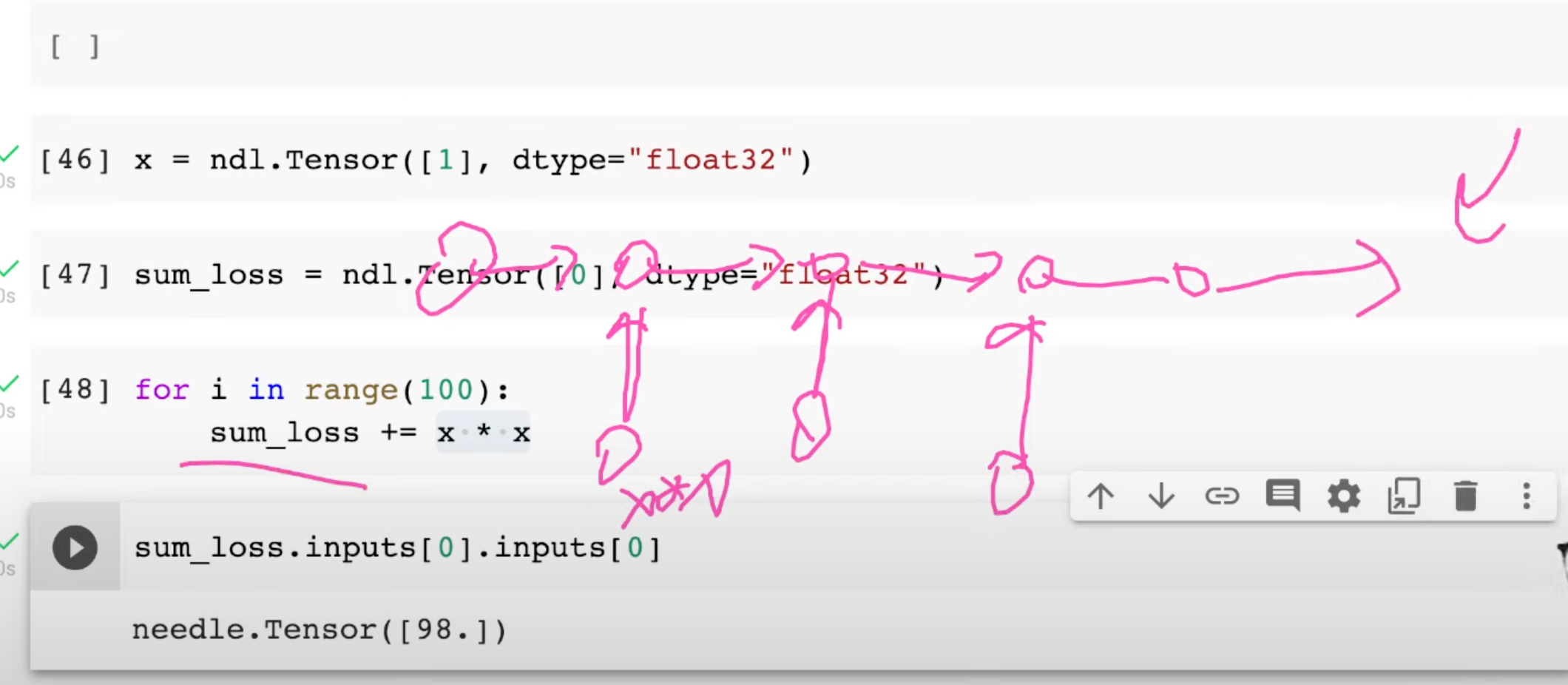
it is costly
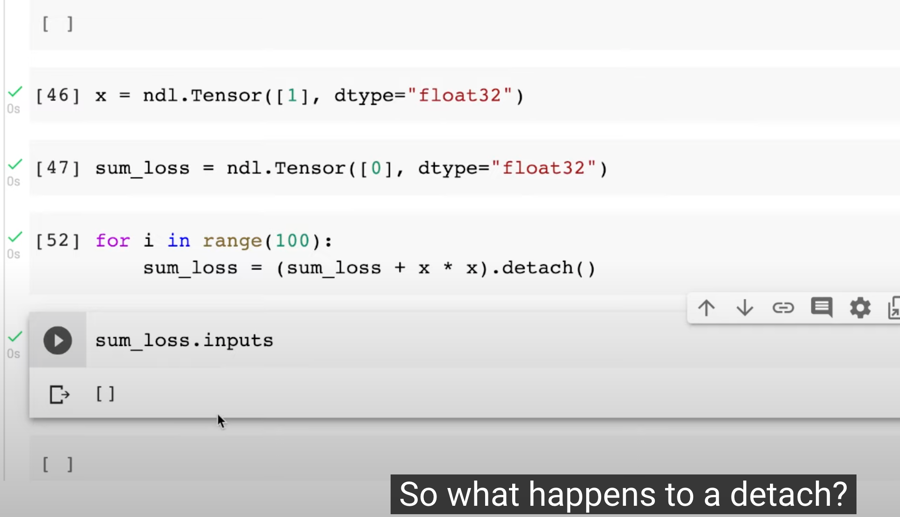
使用 detach
使用
numpy的库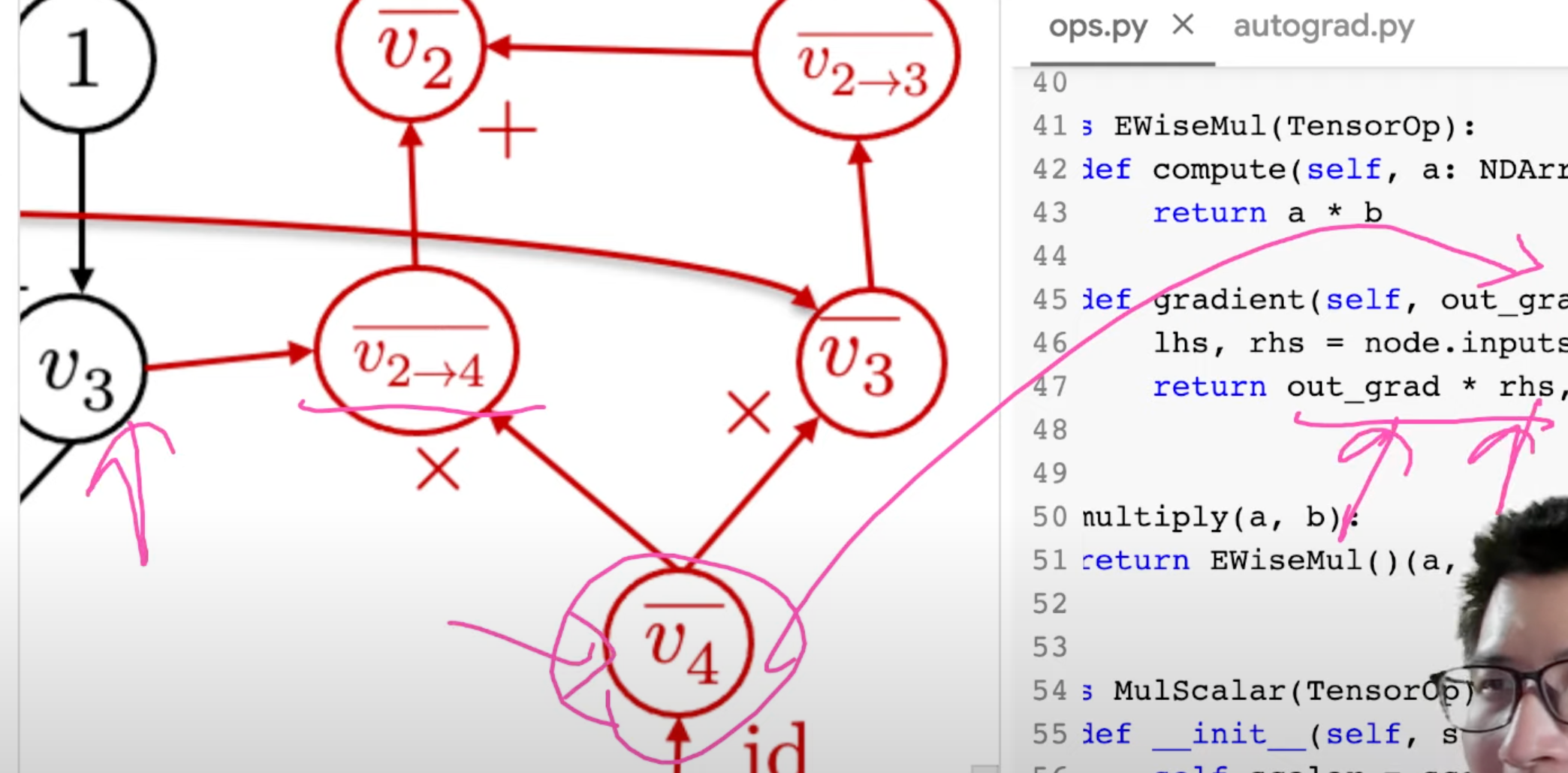
out_grad =v4, lhs=v2,rhs=v3, v2−4=v4v3